In this blog post, we’ll review the new User-Defined Function (UDF) and User-Defined Aggregate (UDA) feature and look into their technical implementation.
For the remaining of this post Cassandra == Apache Cassandra™
The UDF/UDA feature has been first premiered at Cassandra Summit Europe 2014 in London. Robert Stupp presented the new features, his slides are available here.
The feature has been released with Cassandra 2.2 and improved by Cassandra 3.0
I User Defined Function (UDF)
A. Rationale
The idea behind UDF and UDA is to push computation to server-side. On small cluster of less than 10~20 machines, either you retrieve all the data and apply the aggregation at the client-side or you push computation to server-side may not yield a huge gain in term of performance. But on big cluster with 100+ node, the gain is real.
Pushing computation server-side helps:
- saving network bandwidth
- simplifying client-code
- accelerating analytics use-case (pre-aggregation for Spark)
B. UDF Syntax
The standard syntax to create an UDF is
CREATE [OR REPLACE] FUNCTION [IF NOT EXISTS]
[keyspace.]functionName (param1 type1, param2 type2, …)
CALLED ON NULL INPUT | RETURNS NULL ON NULL INPUT
RETURN returnType
LANGUAGE language
AS '
// source code here
';
- You can use CREATE OR REPLACE FUNCTION or CREATE FUNCTION IF NOT EXISTS but it is forbidden to use CREATE OR REPLACE FUNCTION IF NOT EXISTS. Indeed REPLACE and IF NOT EXISTS clauses are mutually exclusive.
- The scope of an UDF is keyspace-wide. Therefore you can add a keyspace prefix to an UDF name.
- Each UDF accepts a list of arguments of the form param 1 type 1, param 2 type 2 … It is very similar to a Java method signature definition.
- There are 2 ways to treat null input. If you use the CALLED ON NULL INPUT clause, the UDF will always be called no matter the input values. Consequently you need to perform null check in the code of your UDF.
- If RETURNS NULL ON NULL INPUT is used, Cassandra will skip the UDF execution and return null if any of the input argument is null.
- You need to specify the return type of your UDF. Please note that the return type as well as input parameters type should be valid CQL types (primitive, collection, tuples or UDT)
- For the language used for your UDF, the possible values are:
- Java
- Javascript (using the NashHorn engine integrated in Java 8)
- Groovy
- Scala
- JRuby
- JPython
Clojure(because of a bug in JSR-223)
- In the source code block, you should escape simple quote whenever possible. Optionally, the code block can use double dollar ($$) as separator instead of simple quote (‘):
AS $$return Math.max(currentVal, nextVal);$$;
C. Demo example
Let’s create a UDF maxOf(currentValue int, testValue int) to take the max of two integers.
CREATE FUNCTION maxof(currentvalue int, testvalue int)
RETURNS NULL ON NULL INPUT
RETURNS int
LANGUAGE java
AS 'return Math.max(currentvalue,testvalue);';
Let’s create a test table and insert some sample data
CREATE TABLE test (
id int,
val1 int,
val2 int,
PRIMARY KEY(id)
);
INSERT INTO test(id, val1, val2) VALUES(1, 100, 200);
INSERT INTO test(id, val1) VALUES(2, 100);
INSERT INTO test(id, val2) VALUES(3, 200);
We use our maxOf UDF to obtain the max value between val1 and val2
SELECT id,val1,val2,maxOf(val1,val2) FROM test WHERE id IN(1,2,3); id | val1 | val2 | udf.maxof(val1, val2) ----+------+------+----------------------- 1 | 100 | 200 | 200 2 | 100 | null | null 3 | null | 200 | null
As you can see, whenever the input argument is null, the UDF just returns null, thus respecting the contract RETURNS NULL ON NULL INPUT
Now let’s change the clause RETURNS NULL ON NULL INPUT to CALLED ON NULL INPUT
CREATE OR REPLACE FUNCTION maxOf(current int, testvalue int) CALLED ON NULL INPUT RETURNS int LANGUAGE java AS $$return Math.max(current,testvalue);$$; >InvalidRequest: code=2200 [Invalid query] message="Function udf.maxof : (int, int) -> int can only be replaced with CALLED ON NULL INPUT"
Interestingly, once you chosed RETURNS NULL ON NULL INPUT, it is no longer possible to modify it. We’ll need to drop and recreate the function
DROP FUNCTION maxOf; CREATE OR REPLACE FUNCTION maxOf(current int, testvalue int) CALLED ON NULL INPUT RETURNS int LANGUAGE java AS $$return Math.max(current,testvalue);$$;
Then let’s use it again:
SELECT id,val1,val2,maxOf(val1,val2) FROM test WHERE id IN(1,2,3); > FunctionFailure: code=1400 [User Defined Function failure] message="execution of 'udf.maxof[int, int]' failed: java.lang.NullPointerException"
The error is expected because we did not have any null check in our UDF.
II User Defined Aggregate (UDA)
Now let’s have a closer look at UDA. The standard creation syntax is:
A. UDA Syntax
CREATE [OR REPLACE] AGGREGATE [IF NOT EXISTS] aggregateName(type1, type2, …) SFUNC accumulatorFunction STYPE stateType [FINALFUNC finalFunction] INITCOND initCond;
- This time, it is not allowed to prefix the UDA name with a keyspace. It is intentional because you are not allowed to use UDF cross the keyspace barrier. In other words you need to be logged into a keyspace to create an UDA.
- The UDA signature is very particular. It only accepts a list of types, not parameter name.
- The SFUNC clause should points to an UDF playing the role of accumulator function
- The STYPE clause indicates the type of the state to be passed to the SFUNC for accumulation. It is also the returned type of the UDA if no FINALFUNC is specified
- You can optionally provide a FINALFUNC to apply a final processing to the state before returning the result
- INITCOND is the initial value of the state. It is optional. This initial state value should be given using CQL syntax
- As for UDF, all types used in UDA definition should be CQL-compatible types.
UDA declaration is very different from UDF declaration and needs some clarification.
First the signature for input argument(s) only specifies the types, no parameter name. It is because there is an implicit constraint between the UDA signature and its SFUNC signature:
CREATE FUNCTION accumulatorFunction(state <state_type>, param1 type1, param2 type2, ...) ... RETURNS <state_type> ...; CREATE AGGREGATE uda(type1, type2, ...) ... SFUNC accumulatorFunction STYPE <state_type> ...;
The accumulatorFunction input types should be the same as the UDA, prepended by the state type (STYPE). The accumulatorFunction returned type should be STYPE.
The optional FINALFUNC, if provided, should have STYPE as the only input type and can return any type.
Consequently, the return type of an UDA is either the STYPE if no FINALFUNC is specified, or is the return type of the FINALFUNC.
Complicated ? Let’s clarify it with an example:
B. UDA Example
We have a counter table that keeps records of number of sold items for each category, each day and each shop
CREATE TABLE sales_items(shop_id text, day int, category text, count counter, PRIMARY KEY((shop_id),day,category)); UPDATE sales_items SET count=count+1300 WHERE shop_id='BestDeals' AND day=20151221 AND category='Books'; UPDATE sales_items SET count=count+5000 WHERE shop_id='BestDeals' AND day=20151221 AND category='Movies'; UPDATE sales_items SET count=count+3493 WHERE shop_id='BestDeals' AND day=20151221 AND category='Games'; UPDATE sales_items SET count=count+1500 WHERE shop_id='BestDeals' AND day=20151222 AND category='Books'; UPDATE sales_items SET count=count+7000 WHERE shop_id='BestDeals' AND day=20151222 AND category='Movies'; UPDATE sales_items SET count=count+9000 WHERE shop_id='BestDeals' AND day=20151222 AND category='Games'; UPDATE sales_items SET count=count+1200 WHERE shop_id='BestDeals' AND day=20151223 AND category='Books'; UPDATE sales_items SET count=count+11000 WHERE shop_id='BestDeals' AND day=20151223 AND category='Movies'; UPDATE sales_items SET count=count+13000 WHERE shop_id='BestDeals' AND day=20151223 AND category='Games'; UPDATE sales_items SET count=count+800 WHERE shop_id='BestDeals' AND day=20151224 AND category='Books'; UPDATE sales_items SET count=count+3000 WHERE shop_id='BestDeals' AND day=20151224 AND category='Movies'; UPDATE sales_items SET count=count+1000 WHERE shop_id='BestDeals' AND day=20151224 AND category='Games'; SELECT * FROM sales_items; shop_id | day | category | count -----------+----------+----------+------- BestDeals | 20151221 | Books | 1300 BestDeals | 20151221 | Games | 3493 BestDeals | 20151221 | Movies | 5000 BestDeals | 20151222 | Books | 1500 BestDeals | 20151222 | Games | 9000 BestDeals | 20151222 | Movies | 7000 BestDeals | 20151223 | Books | 1200 BestDeals | 20151223 | Games | 13000 BestDeals | 20151223 | Movies | 11000 BestDeals | 20151224 | Books | 800 BestDeals | 20151224 | Games | 1000 BestDeals | 20151224 | Movies | 3000
Now we want to have an aggregate view of sales count over a period of time for each category of item. So let’s create an UDA for this!
First we need to create the accumulatorFunction
CREATE OR REPLACE FUNCTION cumulateCounter(state map<text,bigint>, category text, count counter)
RETURNS NULL ON NULL INPUT
RETURNS map<text,bigint>
LANGUAGE java
AS '
if(state.containsKey(category)) {
state.put(category, state.get(category) + count);
} else {
state.put(category, count);
}
return state;
';
> InvalidRequest: code=2200 [Invalid query] message="Could not compile function 'udf.cumulatecounter'
from Java source: org.apache.cassandra.exceptions.InvalidRequestException:
Java source compilation failed:
Line 3: The operator + is undefined for the argument type(s) Object, long
Line 5: Type safety: The method put(Object, Object) belongs to the raw type Map.
References to generic type Map<K,V> should be parameterized
Surprisingly it fails. The reason of the failure is that the map state we are using in our source code is not parameterized, it’s a raw Map so the Java compiler cannot guess that state.get(category) is a Long value instead of a plain Object …
It’s is disappointing since in the definition of the UDF, we provide the generic types for the map (map
A simple fix in our case is to force a cast to Long: (Long)state.get(category) + count. After that, the cumulateCounter UDF does compile.
Now let’s create our UDA to group all items by category and count them
CREATE OR REPLACE AGGREGATE groupCountByCategory(text, counter)
SFUNC cumulateCounter
STYPE map<text,bigint>
INITCOND {};
The input type is (text, counter). Text for the category column and counter for the count column. However the STYPE is map<text,bigint> and not map<text,counter> because counter values are converted straight to bigint (Long).
The INITCOND represents the initial value of the STYPE. This should be an empty map, thus { } (CQL syntax for empty map)
Once done, let’s calculate the number of items sold for each category between 21st and 24th of December:
SELECT groupCountByCategory(category,count)
FROM sales_items
WHERE shop_id='BestDeals'
AND day>=20151221 AND day<=20151224;
groupcountbycategory(category, count)
--------------------------------------------------
{'Books': 4800, 'Games': 26493, 'Movies': 26000}
A simple verification on the original dataset proves that our UDA works as expected.
So far so good. Now that we have an UDA that can simulate a GROUP BY of SQL, we want to push further. Is it possible to filter on the grouped values ? In other words, is it possible to have an equivalent of the HAVING clause of SQL ?
For this, let’s try to inject a FINALFUNC to our UDA to filter the final state!
We need to define first the FINALFUNC so that we can extract the grouped values for category ‘Books’ only.
CREATE OR REPLACE FUNCTION bookCountOnly(state map<text,bigint>)
RETURNS NULL ON NULL INPUT
RETURNS bigint
LANGUAGE java
AS '
if(state.containsKey("Books")) {
return (Long)state.get("Books");
} else {
return 0L;
}';
Then update our UDA
CREATE OR REPLACE AGGREGATE groupCountByCategory(text, counter)
SFUNC cumulateCounter
STYPE map<text,bigint>
FINALFUNC bookCountOnly
INITCOND {};
> InvalidRequest: code=2200 [Invalid query] message="Cannot replace aggregate groupcountbycategory,
the new return type bigint is not compatible with the return
type map<text, bigint> of existing function"
Again, we need to drop and recreate our UDA because the returns type has changed …
If we apply again the UDA on our example dataset:
SELECT groupCountByCategory(category,count) FROM sales_items WHERE shop_id='BestDeals' AND day>=20151221 AND day<=20151224; groupcountbycategory(category, count) -------------------------------------------------- 4800
Et voilà!
The attentive reader will complain because it’s not quite flexible. What if we want now a group by for ‘Games’ category and not ‘Books’ ? Why don’t we add an extra argument to our UDF that will act as a filter for category ?. Something like:
CREATE OR REPLACE FUNCTION
cumulateCounterWithFilter(state map<text,bigint>, category text, count counter, filter text)
RETURNS NULL ON NULL INPUT
RETURNS map<text,bigint>
LANGUAGE java
AS '
if(category.equals(filter)) {
if(state.containsKey(category)) {
state.put(category, (Long)state.get(category) + count);
} else {
state.put(category, count);
}
}
return state;
';
CREATE OR REPLACE AGGREGATE groupCountHaving(text, counter, text)
SFUNC cumulateCounterWithFilter
STYPE map<text,bigint>
INITCOND {};
SELECT groupCountHaving(category,count, 'Books')
FROM sales_items
WHERE shop_id='BestDeals'
AND day>=20151221 AND day<=20151224;
> [Syntax error in CQL query] message="line 1:40 no viable alternative at
input 'Books' (SELECT groupCountHaving(category,count, ['Book]...)">
Arggg !!! Groß problem! Currently it is not possible to have literal value as UDF/UDA parameter!. So disappointing! I filed CASSANDRA-10783 to allow literal value. It turns out that the issue is related to method overloading.
Indeed, when you apply an UDF/UDA on a CQL column, the type of each input argument is known for sure because the CQL column type is provided by the schema. If we have defined many maxOf functions with different input types:
- maxOf(currentvalue int, nextvalue int)
- maxOf(currentvalue bigint, nextvalue bigint)
Calling SELECT maxOf(val1, 100) … is very ambiguous because Cassandra can’t coerce 100 to an appropriate type, int and bigint are both sensible choices…
C. UDA Execution
Below is the steps executed by an UDA:
- Init the state value with INITCOND if provided, or null
- For each row:
- call SFUNC with previous state + params as input arguments
- update state with SFUNC returned value
- If no FINALFUNC is defined, return the last state
- Else apply FINALFUNC on the last state and return its output
As we can see, UDA execution carries a state around, which make it quite hard, if not impossible (at least with regard to the current implementation) to distribute its computation on many nodes.
III Native UDF and UDA
Cassandra 2.2 and 3.0 are shipped with some system functions and aggregates:
System functions
- blobAsXXX() where XXX is a valid CQL type
- XXXAsBlob() where XXX is a valid CQL type
dateOf(), now(), minTimeuuid(), maxTimeuuid(),unixTimestampOf()- toDate(timeuuid), toTimestamp(timeuuid), toUnixTimestamp(timeuuid)
- toDate(timestamp), toUnixTimestamp(timestamp)
- toTimestamp(date), toUnixTimestamp(date)
- token()
- count(1)/count(*)
- writetime()
- ttl()
- toJson(), fromJson()
- uuid()
System aggregates
- count()
- avg(), min(), max(), sum()
Please note that the avg(), min(), max() and sum() functions are defined for Byte, Decimal, Double, Float, Int32, Long, Short and VarInt input types using method overloading.
IV Technical implementation
In this chapter, we’ll see how UDF and UDA are implemented internally in Cassandra.
A. UDF/UDA creation
Below are different steps for UDF/UDA creation:
For Cassandra 2.2
- UDF/UDA definition sent to coordinator
- The coordinator checks for user permission for function CREATE/ALTER
- The coordinator ensures that UDF/UDA is enabled in cassandra.yaml file (enable_user_defined_functions = true)
- If the UDF language is Java, the coordinator will compile it using Eclipse ECJ compiler (not Javac because of licence issues)
- If the UDF language is NOT Java, the appropriate javax.script.ScriptEngine is called to compile the source code
- The coordinator loads the UDF in a child classloader of the current classloader
- The coordinator announces a schema change (UDF and UDA are considered as schema metadata) to all nodes
For Cassandra 3.x, there are some additional steps to control the source code and avoid bad code execution server-side
- UDF/UDA definition sent to coordinator
- The coordinator checks for user permission for function CREATE/ALTER
- The coordinator ensures that UDF/UDA is enabled in cassandra.yaml file (enable_user_defined_functions = true)
- If the UDF language is Java, the coordinator will compile it using Eclipse ECJ compiler (not Javac because of licence issues)
- If the UDF language is NOT Java, the appropriate javax.script.ScriptEngine is called to compile the source code
- The coordinator verifies the compiled byte-code to ensure that:
- there is neither static nor instance code block (code block that are outside of a method body). The idea is to forbid code execution outside the call of UDF
- there is no constructor/method declaration. It will discourage complex code bloc e.g. complex computation in UDF
- there is no inner class declared, same goal as above
- there is no synchronized block. Do you want to break the server ?
- some forbidden classes (like java.net.NetworkInteface) are not accessed
- some forbidden methods (like Class.forName()) are not called
- The coordinator loads the UDF in a separated classloader from the current classloader
- The loaded UDF class is verified against a whitelist that it imports only allowed classes
- The loaded UDF class is verified against a blacklist that it does not import forbidden classes (like java.lang.Thread for example)
- The coordinator announces a schema change (UDF and UDA are considered as schema metadata) to all nodes
Please note that all the above steps for UDF/UDA compilation will be repeated on all nodes after the schema change message. Normally if the UDF has compiled successfully and has been verified on the coordinator, their compilation and verification should pass on other nodes too.
B. UDF/UDA execution
For Cassandra 2.2, the UDF is executed by the caller thread (normally the thread that is in charge of the CQL statement execution). There is no other control for UDF/UDA execution so you better pay attention to the source code you want to execute server-side.
For Cassandra 3.0, if the flag enable_user_defined_functions_threads is turned ON (it is by default), there are some extra checks and sandboxing to avoid evil code execution and prevent people from shooting on their foot:
- The UDF/UDA execution is done using a dedicated ThreadPool
- If user_defined_function_fail_timeout (defaults to 1500 millisecs) is reached, abort
- If user_defined_function_warn_timeout is reached, emit a WARNING message in the log and retry the execution with a new timeout = user_defined_function_fail_timeout – user_defined_function_warn_timeout
C. Some gotchas
Below is a network diagram of an UDF execution:
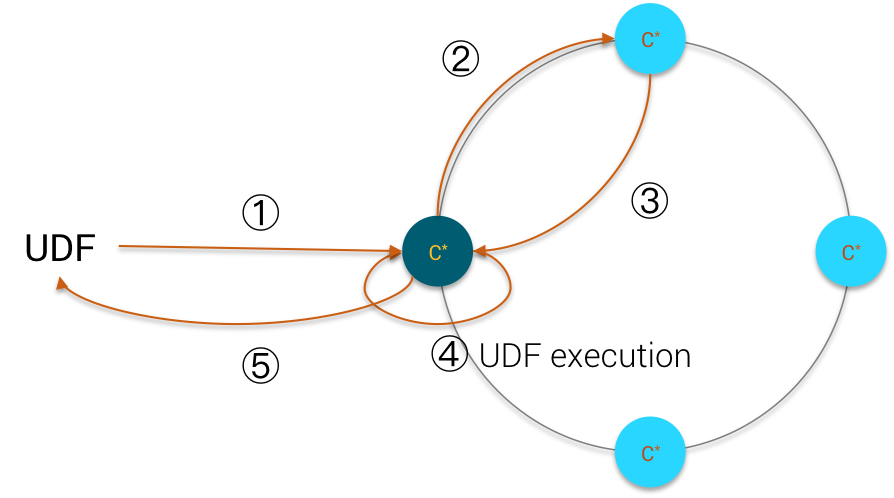
UDF Execution
The attentive reader should wonder, why doesn’t Cassandra execute the UDF on the replica node rather than on the coordinator node ?
The answer is pretty obvious. With an eventual consistency model, Cassandra needs to retrieve all copies of the data from different replicas first on the coordinator, then reconcile them (using Last Write Win) and finally apply the UDF. Cassandra cannot apply the UDF locally because the data values may differ from different replicas.
The only moment the UDF is applied locally on the replica node is when using consistency level ONE/LOCAL_ONE and using a TokenAwareLoadBalancing strategy from the client so that the coordinator is a replica itself
The same remarks applies to UDA execution:
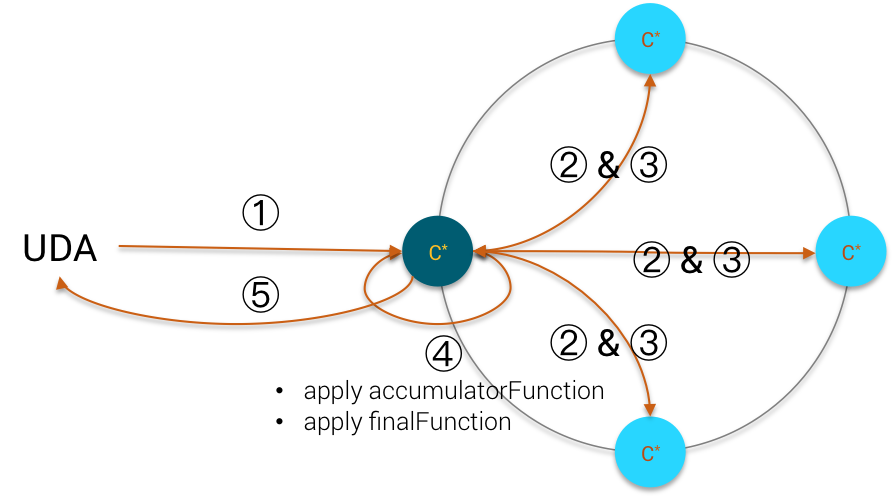
UDA Execution
Consequently, you should pay attention not to apply UDA on a huge number of CQL rows because they will be kept on coordinator JVM heap memory for reconciliation before execution of UDA.
The only cases when the above recommendation can be loosened are:
- when you use ONE/LOCAL_ONE consistency so that data are fetched locally
- when you use UDA in Spark because the Spark/Cassandra connector restricts the query to local token ranges for each node and uses LOCAL_ONE consistency by default
V The future of UDF/UDA
Although quite limited in their usage right now (no literal as input arg for example), UDF/UDA is only the first building block for more promising features in Cassandra:
- Functional index (CASSANDRA-7458)
- Partial index (CASSANDRA-7391)
- WHERE clause filtering with UDF
- UDF/UDA used for building Materialized Views
- …
The future looks bright folks!
Pingback: The importance of single-partition operations in Cassandra
“The scope of an UDF is keyspace-wide. Therefore you can add a keyspace prefix to an UDF name.” according to documentation, UDF is defined within a keyspace : https://docs.datastax.com/en/cql/3.3/cql/cql_using/useCreateUDF.html
ahh, I cannot edit my comment, I understood it wrongly, sorry – please remove it 🙂
hello there,i don’t know the reason my state function is created,aggregated function is also created but when i call that function getting empty map.
please suggest me why this is happening,there is no any error.I goggle it but no where i got answer for the same.