This blog post is the 5th from the series Gremlin Recipes. It is recommended to read the previous blog posts first:
I London_Tube dataset
To illustrate this series of recipes, you need first to create the schema for London_Tube and import the data.
The graph schema of this dataset is :

LondonTube_Schema
The schema is pretty simple, we have a single vertex label station with the following properties:
- name: the station name
- lines: a collection of tube lines to which this station belongs
- is_rail: whether the staton belongs to the railway system
- zone: the zone in which the station belongs to. It is not an integer since zone 2.5 can exists …
INSERTING DATA
First, open the Gremlin console or Datastax Studio (whichever works fine) and execute the following statements:
:remote connect tinkerpop.server conf/remote.yaml session-manage
:remote config timeout max
:remote console
system.graph('London_Tube'). ifNotExists().create()
:remote config alias g London_Tube.g
schema.clear();
schema.propertyKey("zone").Double().single().create();
schema.propertyKey("line").Text().single().create();
schema.propertyKey("name").Text().single().create();
schema.propertyKey("id").Int().single().create();
schema.propertyKey("is_rail").Boolean().single().create();
schema.propertyKey("lines").Text().multiple().create();
schema.edgeLabel("connectedTo").multiple().properties("line").create();
schema.vertexLabel("station").partitionKey("id").properties("name", "zone", "is_rail", "lines").create();
schema.vertexLabel("station").index("search").search().by("name").asText().by("zone").by("is_rail").by("lines").asText().add();
schema.vertexLabel("station").index("stationByName").materialized().by("name").add();
schema.vertexLabel("station").index("toStationByLine").outE("connectedTo").by("line").add();
schema.vertexLabel("station").index("fromStationByLine").inE("connectedTo").by("line").add();
schema.edgeLabel("connectedTo").connection("station", "station").add();
schema.config().option("tx_autostart").set(true);
// Load data from file london_tube.gryo
graph.io(IoCore.gryo()).readGraph("/path/to/london_tube.gryo");
The file london_tube.gryo can be downloaded here
II Path object
In this post we will explore the usage of Gremlin path object. Let’s say we want to know the “path” between the station South Kensington and all its neighbours stations. First let’s create a classical traversal:
gremlin>g.V().
has("station", "name", "South Kensington").
union(identity(), both("connectedTo"))
Please notice the usage of both("connectedTo"). Indeed the direction of the connection between 2 stations does not matter but since Gremlin is a directed graph we need to use both().
The step union(identity(), both("connectedTo")) will output the original station South Kensington along side with its neighbours.
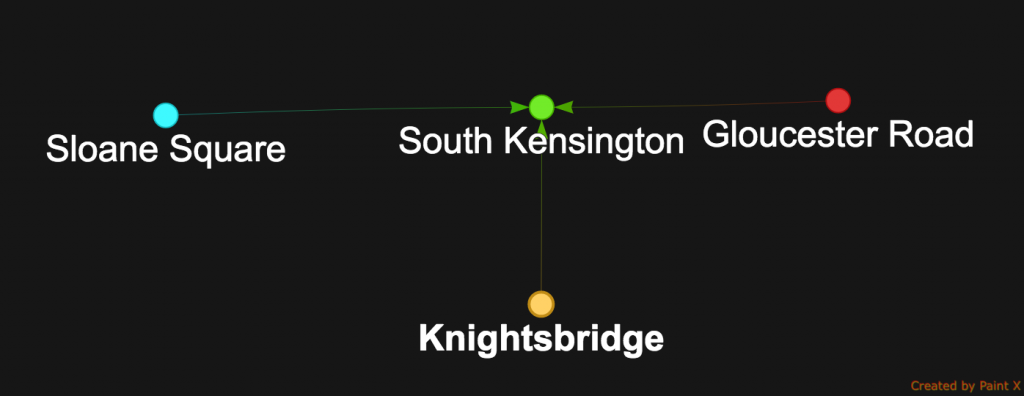
SouthKensington_neighbours
So what is a “path” in Gremlin ? According to the JavaDoc:
A Path denotes a particular walk through a Graph as defined by a Traversal. In abstraction, any Path implementation maintains two lists: a list of sets of labels and a list of objects. The list of labels are the labels of the steps traversed. The list of objects are the objects traversed.
In a nutshell, the path object implements the interface Iterator<Object>
- all labels created on the traversal (using the modulator
as("label")) - all vertices visited by the traversal
- all edges visited by the traversal
- all side-effects or data structures created during the traversal
To display the path that connects South Kensington to its neighbours:
gremlin>g.V().
has("station", "name", "South Kensington"). // Iterator<Station>
both("connectedTo"). // Iterator<Station>
dedup().
path() // Iterator<Path> == Iterator<Iterator<Object>>, Object == Vertex/Edge ...
==>[v[{~label=station, id=236}], v[{~label=station, id=99}]]
==>[v[{~label=station, id=236}], v[{~label=station, id=146}]]
==>[v[{~label=station, id=236}], v[{~label=station, id=229}]]
We can see there are 3 paths that connect South Kensington to its neighbours. To make the display nicer let’s project the path object on their property “name” to display station names:
gremlin>g.V().
has("station", "name", "South Kensington"). // Iterator<Station>
both("connectedTo"). // Iterator<Station>
dedup().
path(). // Iterator<Path> == Iterator<Iterator<Object>>, Object == Vertex/Edge ...
by("name") // Iterator<Iterator<String>>
==>[South Kensington, Gloucester Road]
==>[South Kensington, Knightsbridge]
==>[South Kensington, Sloane Square]
We want Gremlin to help us finding the path between South Kensington and Covent Garden using the Piccadilly line:
gremlin>g.V().
has("station", "name", "South Kensington").
emit().
repeat(timeLimit(200).both("connectedTo"). // Expand the graph on edge "connectedTo"
filter(bothE("connectedTo").
has("line",Search.tokenPrefix("Piccadilly"))). // Only retain stations connected by "Piccadilly"
simplePath()). // Simple path to avoid cyclic loops
has("name", "Covent Garden"). // Only retain target station "Covent Garden"
path().unfold()
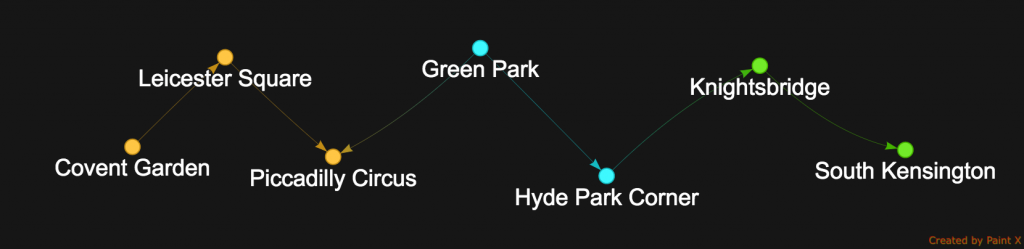
SouthKensington_CoventGarden
We purposely put emit() before the repeat() step so that the original South Kensington station is emitted alongside with all other stations on the journey.
For the repeat() step, instead of putting a limit in term of number of times we traverse the connectedTo edge with the step times(x), we rather set a time limit to avoid graph explosion with timeLimit(200).
We only collect stations which belong to the Piccadilly line with the prefix search filtering has("line", Search.tokenPrefix("Piccadilly")). This predicate is DSE specific and is leveraging DSE Search. The filtering is performed on adjacent edges “connectedTo” thus the step filter(bothE("connectedTo") ...)
Finally we filter the target station to match Covent Garden with the step has("name", "Covent Garden"). If we were to stop our traversal at this step, there will be a single displayed station, which is Covent Garden.
What we want is different: all the stations of the journey from South Kensington to Covent Garden and here path() step comes in handy.
Since we only visit vertices on our traversal, the step path is of type Iterator<Iterator<Vertex>>, the outer Iterator represents the Traversal object itself. To access the inner Iterator<Vertex> we need to use the unfold() operator.
So consequently path().unfold() become an Iterator<Station> and will display all stations from South Kensington to Covent Garden
We can check the result against the real London tube map
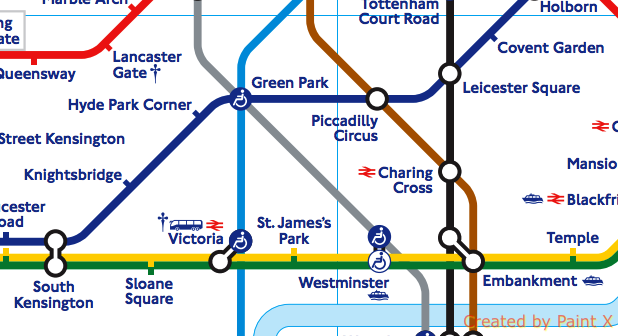
London_Tube_Map_Piccadilly
III Finding shortest path
Now let’s say we want to go from South Kensington to Marble Arch, if we look at the London tube map, there are 2 possible journeys:
- the one that minimizes station count going through Green Park & Bond Street (5 stations) but we have 2 line changes:
Picadilly line -> Jubilee line and then Jubilee line -> Central line - the one that minimizes the number of line changes going through Notting Hill Gate but with more stations (6)
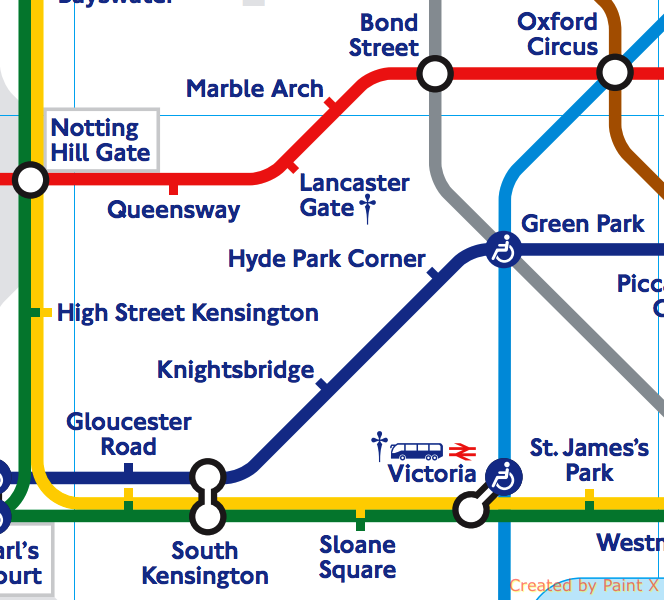
SouthKensington_MarbleArch
So let’s see how we can ask Gremlin to find the path that minimizes station count:
gremlin>g.V().
has("station", "name", "South Kensington"). // Iterator<Station>
emit().
repeat(both("connectedTo").simplePath().timeLimit(400)). // Iterator<Station>
has("name", "Marble Arch"). // iterator.filter(station -> station.getName().equals("Marble Arch"))
order(). // order all the paths leading to Marble Arch
by(path().count(local), incr). // by number of elements(station) in each path, ASC
limit(1). // take the 1st path == shortest path
path().unfold() // Iterator<Station>
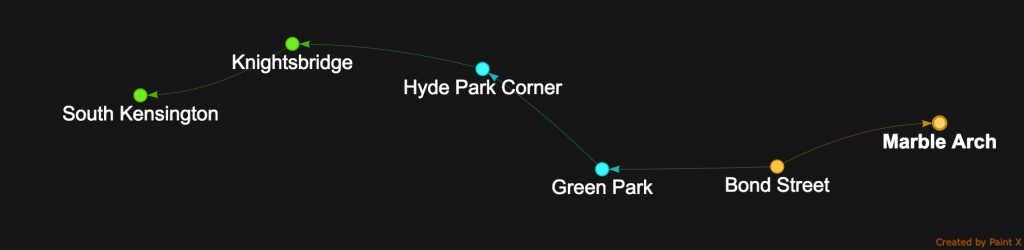
SouthKensington_MarbleArch_Path1
Let’s analyse the above traversal. First repeat(both("connectedTo").simplePath().timeLimit(400)) represent graph expansion in all directions from South Kensington but time-limited to 400ms. has("name", "Marble Arch") will filter all emitted stations to take only those who are Marble Arch.
At this stage we have have multiple journeys leading to the same destination. Now the fun begin with the path object. order().by(path().count(local), incr) will order each found journey by the number of “object” found in the path history. The trick here is that path() represents a collection of path history e.g. Iterator<Iterator<Station>> and we want to sort them by the station count, thus count(local). Taking the 1st matching path will guarantee us the journey with the minimum station count.
The last path().unfold() is just for display purpose. We want to show the complete list of stations leading from South Kensington to Marble Arch
What if we want to minimize the number of line changes instead ? Path again! Minimizing the number of line changes is equivalent to order all the journeys by the number of distinct line values of the “connectedTo” edge in each path and then take the minimum.
gremlin>g.V().
has("station", "name", "South Kensington").
emit().
repeat(bothE("connectedTo").otherV().simplePath()). // instead of both("connectedTo"), we do bothE("...").otherV() to collect edges on the path and save it as "paths"
until(has("name", "Marble Arch").or().loops().is(eq(6))). // limit graph expansion to max 6 hops
has("name", "Marble Arch").
order().by(
path().unfold(). // Iterator<Object> where Object == Station & Edge "connectedTo"
hasLabel("connectedTo"). // only take edges "connectedTo"
values("line").dedup().count(), // take the line value on the edge, dedup & count
incr). // ORDER BY COUNT DISTINCT LINE NUMBER on the path, ASC
limit(1).
path().unfold().
hasLabel("station")
The beginning of the traversal is quite similar but now instead of doing both("connectedTo") we did bothE("connectedTo").otherV(). Semantically it is equivalent but the subtle difference is that now we are visiting also all “connectedTo” edges in our traversal, not only station vertices, and it is done on purpose.
Instead of using timeLimit(400) we can also use the until(has("name", "Marble Arch").or().loops().is(eq(6))) step to stop graph expansion whenever we find Marble Arch or whenever we exceed 6 hops from South Kensington.
Now the ordering step is important. We unfold the path object, which now becomes an Iterator of Station vertices and “connectedTo” edges. We want to select only “connectedTo” edges thus hasLabel("connectedTo"). Then we extract the “line” property, deduplicate them and count them. The ordering will be done on this distinct lines count, ASCENDING.
The traversal ends with a path().unfold() to display nicely the journey, with an additional filtering hasLabel("station") to remove all the “connectedTo” edges from the path.
The result is what we expected:
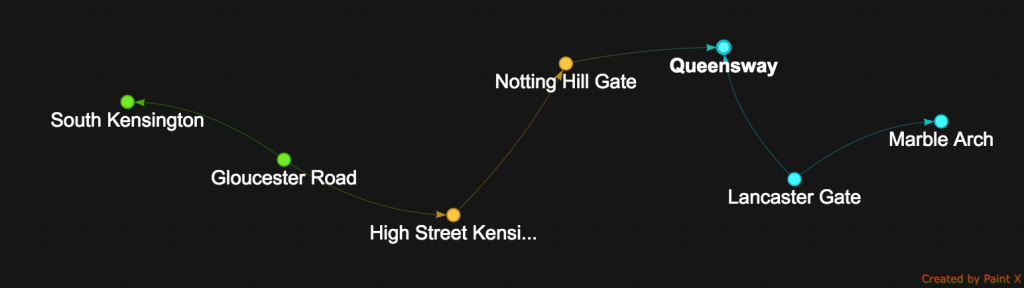
SouthKensington_MarbleArch_Path2
And that’s all folks! Do not miss the other Gremlin recipes in this series.
If you have any question about Gremlin, find me on the datastaxacademy.slack.com, channel dse-graph. My id is @doanduyhai